
Just a few short years ago microservices were a curiosity discussed by developers with a kind of giddy excitement at the possibilities and opportunities the fledgling app architecture presented.
Today, even us networky folks are talking about them because they’ve pretty much become – as the latest research from Lightstep declares – mainstream in the enterprise. Seriously. In our 2018 State of Application Delivery report, even network-related roles indicated they desired application services to be served up in containers. So it should not be a surprise to find that the aforementioned Lightstep survey found that not only do 91% of their respondents use or plan to use microservices, but 86% also expect them to be the default within five years.
That’s not to say that there aren’t challenges. In fact, 99% of respondents in Lightstep’s survey reported challenges when using microservices. From the responses, one could reasonably say that pretty much everything is more difficult (and sometimes expensive) with microservices.
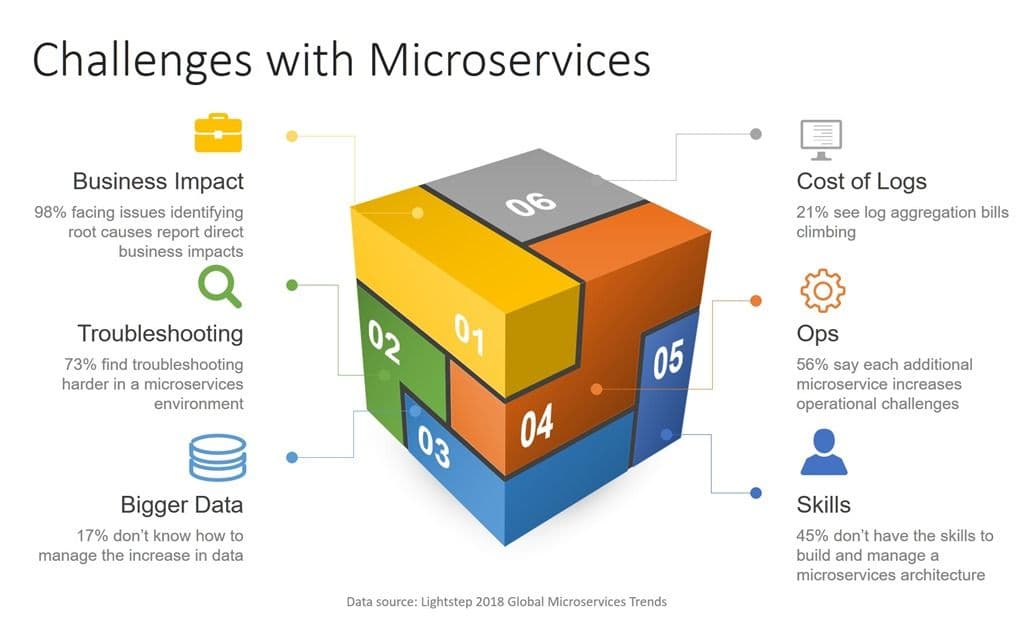
The survey noted both business and operational challenges ranging from the cost of log aggregation rising (21%) to not knowing what to do with the increase in data (17%) to difficulties with troubleshooting problems (73%).
More troubling, however, was the finding that “98% of those that face issues identifying the root cause of issues in microservices environments report it has a direct business impact.”
This is one of the key challenges echoed elsewhere, usually using the terms “visibility” or “observability”, depending on whether you’re on the network side of the fence or hanging with DevOps.
Both essentially describe the same capabilities – being able to see what’s going on as messages are traversing the network from client to service and back. Inside the container environment, this is particularly challenging because of the scope and scale of the services involved.
With a traditional three-tier web app you have three sets of logs and three systems you need to track. With a microservices architecture – likely fronted by an API that’s potentially used by both web and mobile clients – you may have tens or hundreds of different services you need to keep track of.
The scaling model is still the same – we’re horizontally scaling (out) with clones – but the magnitude within a container environment is significantly larger. It’s like playing whack-a-mole with a hundred holes instead of ten. Figuring out the path any given transaction took is going to be challenging, to say the least. Especially when the path may have disappeared. After all, the premise of most container environments is to fail fast and replace instances rather than wait for manual intervention.
There are a couple of ways to address this challenge. First and foremost is instrumentation that assists in tracing and troubleshooting. This approach is not new but it is made more challenging by the volatile nature of container environments. Still, insertion of tracing elements (such as custom HTTP headers with unique identifiers) can be a huge boon to ops when trying to track down errors or performance problems. While typically not a capability of native container scaling options, it is one that service meshes are tackling as part of their offerings.
Second is the ability to quarantine ailing microservices to allow ops and dev to examine the system in the state that caused it to fail. Quarantine basically removes the ailing container from the active environment so calls are no longer sent to it, but keeps it alive for analysis and inspection.
There is no magic wand, but being able to track and quarantine containers in microservices-based deployments can go along way toward lowering the mean time to resolution (MTTR) and reducing the impact on the business.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.