
Traditional visibility, aka Monitoring 1.0, is all about information. Probes, agents, logs, and traces offer a wealth of digital health data. It comes from systems, from infrastructure, from the network, from platforms. It is generated in real-time and post-process. It is created in droves, measured not by KB today but in GB.
Honestly, we have enough data.
What we don’t have is the product of that data; we don’t always have the insights that lead to positive corrective action.
Too often we have only binary status indicators. Red is bad. Green is good. And even when we’re aware there’s a problem, we aren’t given enough information to figure out where the problem began. Yes, app A is performing poorly, and users are complaining. But why? Is it the network? Their device? The platform? The orchestration environment?
Even assuming we figure out quickly it’s the network, we aren’t offered any insight as to why it’s so congested. Is it too many users? Someone offering a sale today? Is it seasonal? Is it because of a recent update?
The variables are voluminous, and the stakes are high. Failure to address the problem of poor user experience can lead to declining revenue, abandoned apps, and loss of reputation. When business is digital, business suffers based on digital conditions.
This is the reality driving us toward observability and beyond, to AIOps. Observability, aka Monitoring 2.0, is a significant step forward in this technology journey for operators and digital business as they strive to understand and stabilize the relationship between user experience and business outcomes. But it’s only half the battle, and the other half involves analytics and automation.
Observability, Analytics, and Automation
Observability is more than just “better visibility.” It’s the ability to provide a picture of what’s going on at a system level. It’s not just a dashboard with network, infrastructure, and app performance plastered in colorful charts. It’s a concerted effort to correlate all the digital health data available to paint a holistic picture of how the user experience is performing right now. It’s the driving force behind operational data platforms and a considerable amount of market activity as providers position themselves to win the coveted mantle of “operational data platform” in every enterprise.
But even achieving that still leaves us battling to address the problems that invariably crop up. If knowing the user experience is half the battle, then the other half is finding out why and then acting on it.
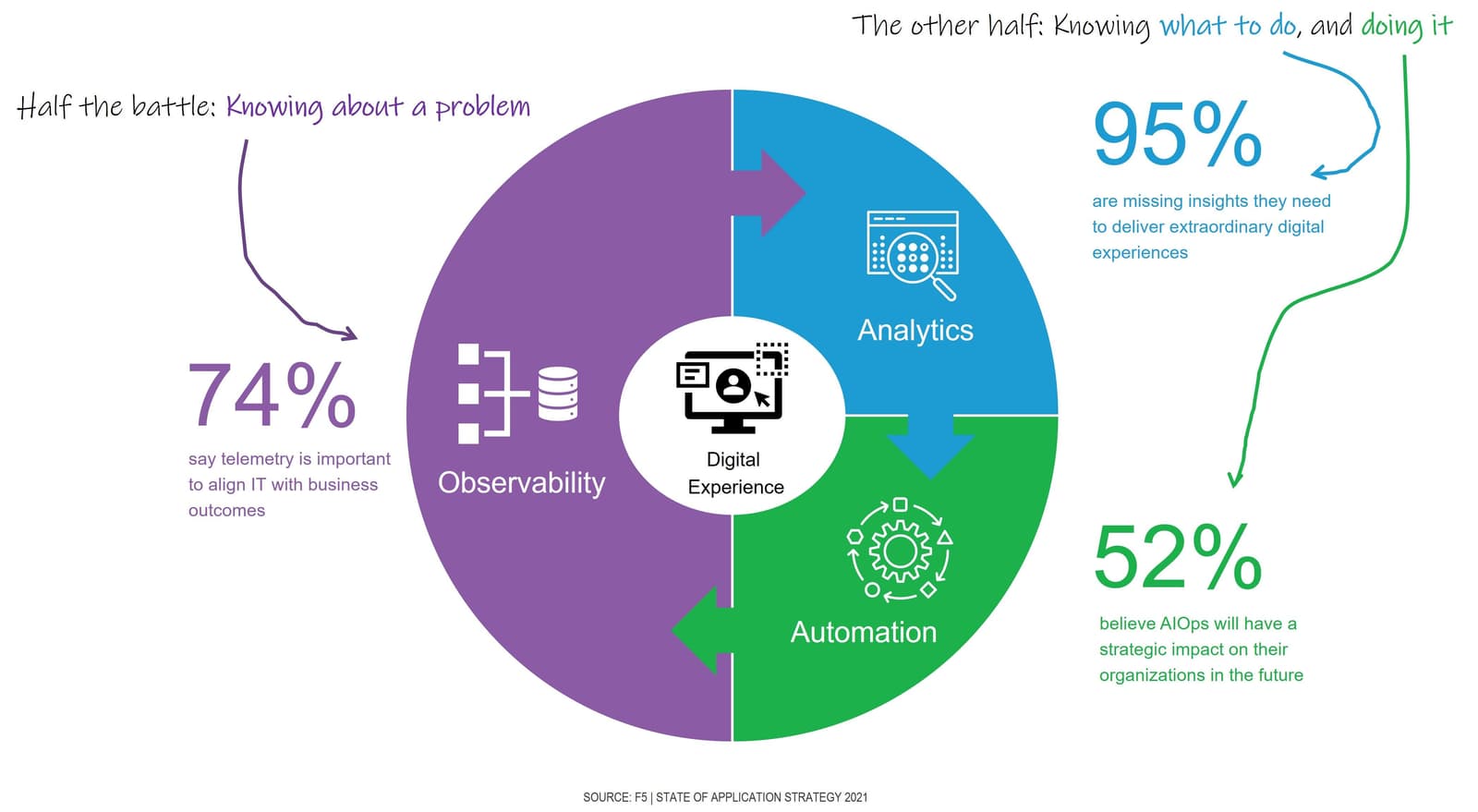
The problem, of course, is the pesky reality that nearly all organizations are missing the insights they need to act in service to an extraordinary digital experience. Traditional analytics are canned queries that can’t identify relationships or recognize patterns in the data that can uncover these missing insights. Machine learning presents a solution, providing the means to churn through voluminous data and discover the insights necessary to address the root cause of performance degradation or identify an attack before it overwhelms services or succeeds in gaining access.
Having the insights isn’t enough, either. The ability to quickly act on those insights to improve performance or halt an attack is also important. Inserting manual review and approvals to make policy changes impedes organizational agility in the face of problems or attack.
We need to rely on compute to react in a timely manner to the insights gleaned from telemetry. Responding five minutes after an attack begins might be too late. Two minutes after a performance degradation is definitely too late based on the impatience of typical consumers. We built compute to be terribly efficient at processing data. Consider that “both in terms of spikes and synaptic transmission, the brain can perform at most about a thousand basic operations per second, or 10 million times slower than the computer.” (Source: Nautilus) We need to leverage that capability to overcome the slow down introduced by manual steps into an otherwise automated process.
If you were to race in the Daytona 500, you wouldn’t stop at every last turn and push your car the rest of the lap, would you? Without embracing a fully autonomic system, that’s what we’re doing to digital experiences.
We have long trusted systems to automatically scale services, and in the future, we will learn to trust them to take corrective action that protects services and data and ensures an extraordinary digital experience for consumers. Over half (52%) of IT decision makers agree that this capability—most often referred to as AIOps—will have a strategic impact on their organization.
This is a fully functional digital experience battle plan: a closed loop, automated operational approach driven by data collected from every layer of the stack.
There are challenges. Make no mistake, this is not a simple solution nor one you can grab off the shelf and implement. Full-stack observability—the ability to gather telemetry from every component from the network to the infrastructure, from the security and delivery technologies to the app—is not as simple as traditional monitoring providers would like. Standard approaches based on agents and probes are neither efficient nor cost effective in an architecture where distributed cloud will be the norm. Native telemetry generation capabilities—such as those achieved through the adoption of Open Telemetry—will be the best way to achieve the full stack observability needed by machine learning-based analytics to quickly and accurately produce actionable insights that align with desired business outcomes.
Automation has a long way to go, as well. With just over half (52%) of organizations treating infrastructure as code today, it is clear many enterprises have yet to go “all in” on automation. Yet this capability is in the critical path. Without it, the closed loop may operate—but at what cost? The impedance introduced by manual operations into this feedback loop will introduce delay that could cost the business customers, reputation, or precious data.
Digital Transformation and Enterprise Architecture
Most organizations today are operating in the second and third phases of digital transformation. Motivated by the necessity to move faster due to the global pandemic, many have made tactical decisions that now need to be incorporated into a strategic approach that readies them to move forward on their digital transformation journey.
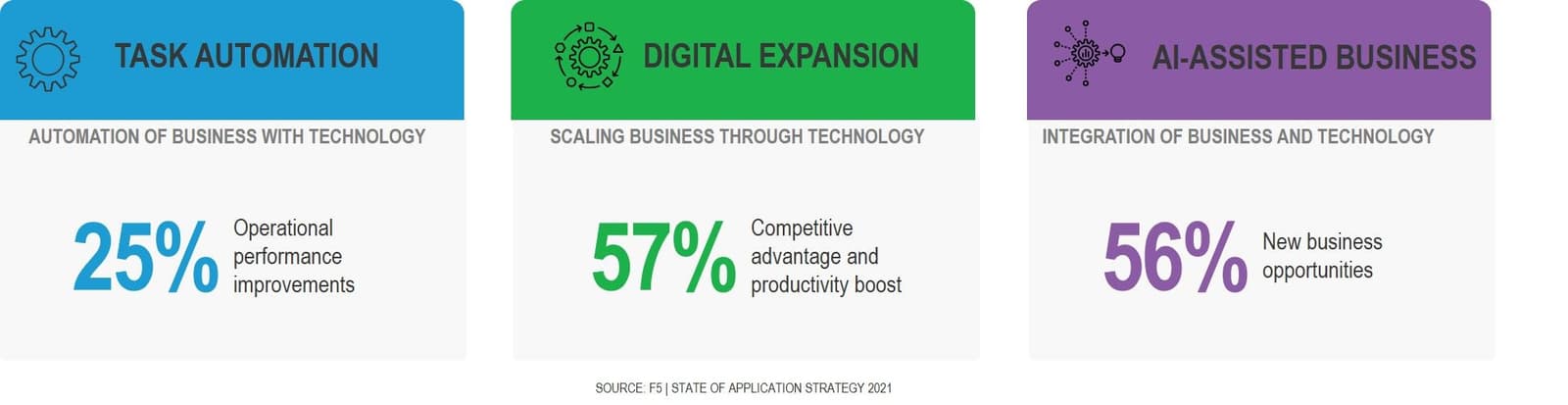
A strategic approach is one that works toward the goal of a closed loop from observability to insights to automation. It’s part of an approach that we call adaptive apps; an approach that offers CIOs an architectural blueprint to modernizing enterprise architecture so IT can close the loop and enable the enterprise to operate as a fully digital business.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Multicloud chaos ends at the Equinix Edge with F5 Distributed Cloud CE
Simplify multicloud security with Equinix and F5 Distributed Cloud CE. Centralize your perimeter, reduce costs, and enhance performance with edge-driven WAAP.

At the Intersection of Operational Data and Generative AI
Help your organization understand the impact of generative AI (GenAI) on its operational data practices, and learn how to better align GenAI technology adoption timelines with existing budgets, practices, and cultures.
Using AI for IT Automation Security
Learn how artificial intelligence and machine learning aid in mitigating cybersecurity threats to your IT automation processes.
Most Exciting Tech Trend in 2022: IT/OT Convergence
The line between operation and digital systems continues to blur as homes and businesses increase their reliance on connected devices, accelerating the convergence of IT and OT. While this trend of integration brings excitement, it also presents its own challenges and concerns to be considered.
Adaptive Applications are Data-Driven
There's a big difference between knowing something's wrong and knowing what to do about it. Only after monitoring the right elements can we discern the health of a user experience, deriving from the analysis of those measurements the relationships and patterns that can be inferred. Ultimately, the automation that will give rise to truly adaptive applications is based on measurements and our understanding of them.
Inserting App Services into Shifting App Architectures
Application architectures have evolved several times since the early days of computing, and it is no longer optimal to rely solely on a single, known data path to insert application services. Furthermore, because many of the emerging data paths are not as suitable for a proxy-based platform, we must look to the other potential points of insertion possible to scale and secure modern applications.