
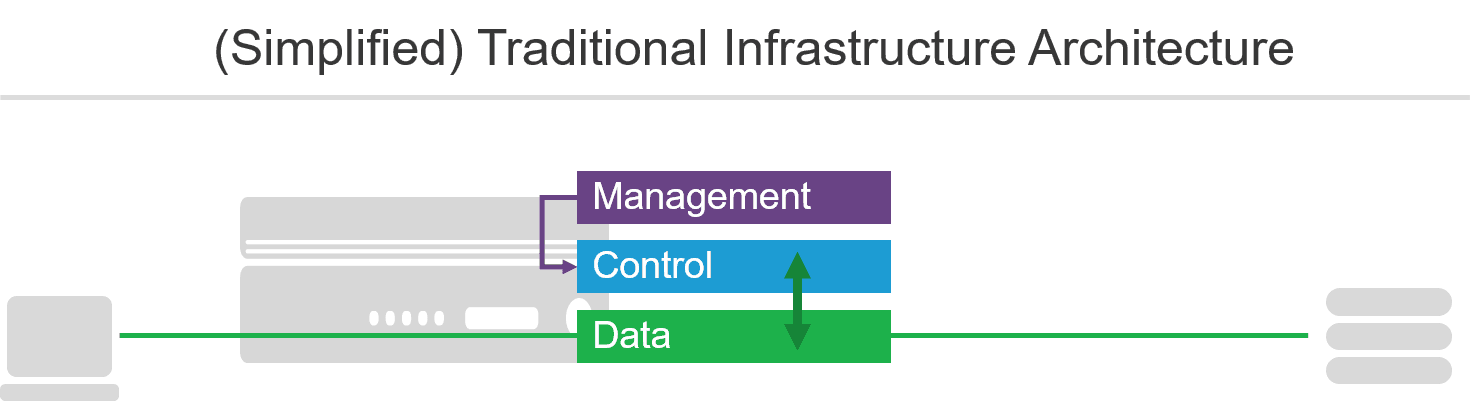
In traditional network infrastructure there are generally three architectural planes associated with network infrastructure: data, control, and management.
The exact definitions for these can vary depending on the genre and specific implementation of infrastructure, but the archetypes are largely accurate for most network infrastructure.
- Data plane
- Sometimes referred to as the data path in modern vernacular, the data plane is the path through which packets (data) are passed. The data plane is responsible for accepting a packet and forwarding it to the right destination.
- Control plane
- Generally, the control plane determines where data is forwarded. Routing protocols are good examples of a control plane functions, as are higher order decision making that today may be more dynamic. The specific implementation varies but can range from the data plane passing data to the control plane for a decision to the control plane transparently observing data and acting on specific triggers. Control planes are often also responsible for monitoring the health of devices and collecting statistics.
- Management plane
- The management plane is the most visible of the three planes because it is where we interact with the control plane. Traditional management planes use CLI (command line interfaces) while modern management planes prefer API (application programming interfaces). Regardless of the method used, the management plane enables operators to set policies that are enforced by the control plane. This includes configuration options such as load balancing algorithms and allow/deny policies based on characteristics like IP address and device type.
But there's another kind of orchestration at work that's under the hood and largely unseen by operators. It has nothing to do with management except that it's appropriating some responsibilities from human operators.
The distinction here is that the actions are triggered automatically by changes to the environment during execution rather than as a deployment event. But the information about what has changed is vital, and that means it has to be obtained somewhere.
In a traditional operational model that information usually comes from change tickets or requests. In the case of modern operational models and, specifically, containers this information comes from service registries via a discovery mechanism.
Service Registries and Discovery
The nature of container environments includes the assumption that IP addresses effectively don't matter to the application environment. But they do matter to infrastructure because data still has to be routed and forwarded from device to device in order to traverse the path between the client and the application. In modern environments, those IP addresses often exist for short periods of time (the lifetime of a container/service).
Consider these findings from DataDog (emphasis added):
The rapid adoption of orchestrators (see fact 4) appears to be driving containers toward even shorter lifetimes, as the automated starting and stopping of containers leads to a higher churn rate. In organizations running an orchestrator, the typical lifetime of a container is about 12 hours. At organizations without orchestration, the average container lives for six days.
From <https://www.datadoghq.com/docker-adoption>
Imagine if you, as an operator, had to update the routing tables or load balancing pools every six days, let alone every twelve hours. You would do little else. The potential for misconfiguration would be significant and likely grow the longer you were forced to operate in manual mode to manage the changes in a container cluster.
A service registry - like Consul - becomes a critical component of your container deployment. Service registries keep track of instances and services and their associated IP addresses. In this respect, they can be likened to a "DNS for containers and services".
So the service registry tracks the current characteristics of containers in the cluster. Discovery is the process of connecting to the service registry (via API or by subscribing to a message queue) of matching instances to IP addresses.
This means that for infrastructure that needs to route traffic to a specific service or instance inside a container cluster, it must be able to retrieve an IP address. Because as much as containers hide the network from the application, they still rely on it to get data from one place to another.
The Fourth Plane: Orchestration
What that does is introduce a new architectural layer into infrastructure that interacts with container orchestration environments. This layer - the orchestration layer - integrates with the container environment and makes use of capabilities like service discovery to automate the discovery of services and instances. That means that a load balancer can automatically discover the members of a pool and continuously update it based on changes in the environment. This alleviates the burden on operations to update load balancing pools manually - and increasingly tedious task when containers are living on average less than one week.
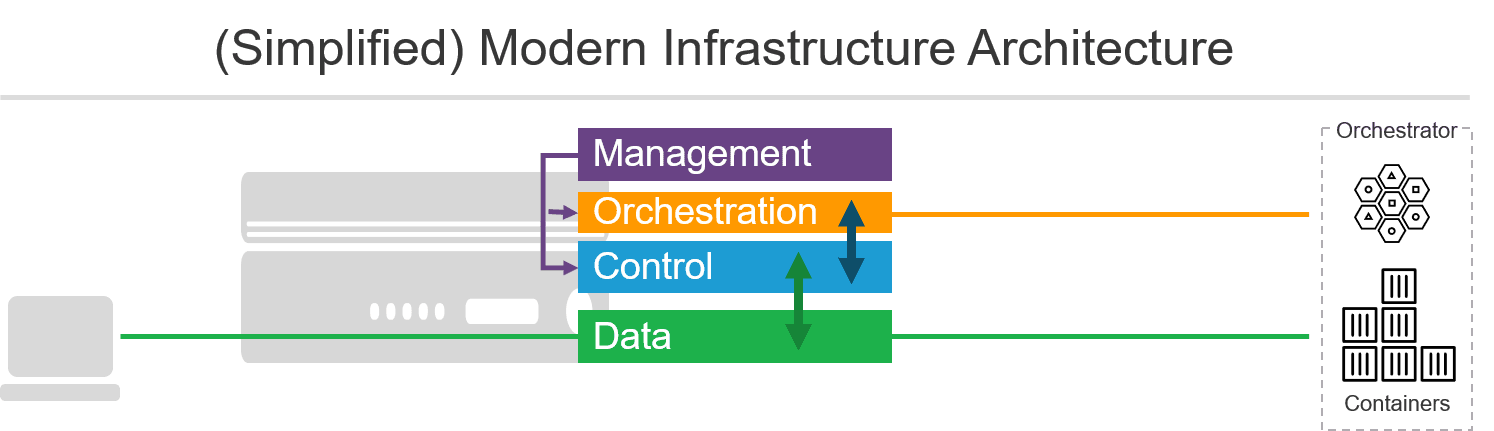
This plane is not meant for interaction with operators. Configuration and monitoring and operation are still accomplished via a management plane. The location of a service registry would be configured via the management plane but used by the orchestration plane to connect and communicate changes to the control plane.
We can define the orchestration plane as follows.
- The orchestration plane is one of the least visible planes in infrastructure architecture. Interaction with it is accomplished via the management plane, which is primarily responsible for pointing the orchestration plane at the appropriate service registry. Its responsibility is to update dynamic components in the control plane to ensure proper forwarding and availability of containerized resources.
Questions still remain whether this plane should be integrated into the device along with the control and data planes or whether it is simply a veneer over the management plane (which would change our diagram slightly but otherwise not impact the interaction between planes and components). Many traditional devices already support this emerging plane by providing extensions that integrate with container environments and make changes via the management plane. This is a nice example of refactoring traditional architectures to extend functionality into modern environments. But ultimately it may not be the ideal solution.
Why Does It Matter?
It may seem at first that the introduction of a fourth plane for infrastructure doesn't matter. After all, its function is removing some responsibility for tedious tasks from operators. That can't be bad.
It isn't bad, but it is important to understand that this move from static to dynamic configuration has consequences for some of the most important functions of the control plane. The criticality of service discovery becomes such that its availability and security should be an imperative. It becomes, in effect, the single point of failure on which your entire application infrastructure rests.
Service registries are built on the same premises that most modern applications rest - they are built to handle failure. You can end up in a situation where the IP address you just discovered disappears before you can forward traffic on to its instance. Most infrastructure is capable of retransmitting at that point, but the process takes time. Microseconds matter in the digital economy, so traditional options like time outs and discovery intervals will make a difference in modern architectures that rely on discovery. Monitoring, too, becomes far more critical as the ability to determine health and availability as quickly as possible can make the difference between a user being satisfied and a user disengaging. Both are business level concerns that everyone in a modern organization should be aware of and building into their own metrics and expectations.
The implementation of the orchestration plane in your infrastructure as well as the choice of service registry become important factors in your decision-making process regarding what technology you use. Consider carefully your choices, as they impact both the availability and performance of applications delivered via container-based architectures.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.