
In April, I wrote about why the old model of software security is broken. That post was about the problem and the principles. This one is about the work that we are doing at F5 to secure our code.
About nine months ago, we started using frontier AI models to systematically scan our own source code for vulnerabilities. What began as an early exploration of what these models could do against a real, production-scale codebase has since become one of the most significant investments in our product organization. We have built dedicated infrastructure, pulled engineering resources from across the company, and made this a top priority at every level of the organization.
F5 is trusted by over 80% of the Global Fortune 500. We support more than half of the world's application delivery controller (ADC) environments. All 15 of the top 15 global banks, 30 of the top 30 U.S. commercial banks, 10 of the top 10 global insurance companies, 10 of the top 10 global telecom companies, and 15 of the top 15 U.S. executive departments run F5 in their infrastructure.
We hold ourselves to a higher standard because organizations put us in their most critical paths: between their users and applications, and their agents and APIs.
The models were not great at first. They are now.
When we started down this path in the fall of 2025, the frontier models available to us were promising but limited. They could identify surface-level issues, but their ability to reason about complex codebases, understand context across modules, and distinguish real vulnerabilities from false positives was inconsistent.
The rate of false positives was high. Very high.
We had to learn a lot of things from scratch:
- How to build an effective harness
- How to structure prompts that provide enough context to reason about real code
- How to build verification pipelines that could separate signal from noise at scale
- How to take the output of one model and use it as input for another to confirm or reject findings
There wasn’t a generic playbook that we could apply to F5, so we had to build one.
The rate of improvement in these models has been astounding. The frontier models from Anthropic and OpenAI, including Claude Mythos and GPT Cyber, can now uncover real vulnerabilities, demonstrate how they can be exploited, and help engineers fix them. In some cases, these models work exceptionally well on binaries and compiled code, not just source code. That was not true last fall.
We’re not the only ones seeing this improvement. We’ve been working closely with some of the largest organizations in the world, including those in Project Glasswing. These are institutions that run F5 in their most critical paths, and they are dealing with the same shift we are.
A few things have become clear:
- The preview and research models are remarkably capable. The latest models from Anthropic and OpenAI can reason about compiled code, identify complex vulnerability chains, and generate sophisticated proofs of concept.
- The rate of model improvement is not linear. It is accelerating. Each new model generation represents a meaningful step function in capability. Organizations that are not running the latest models against their code are falling behind.
- False positives were the initial bottleneck, not the models themselves. When we started, the signal-to-noise ratio was punishing. We had to invest heavily in building verification harnesses, triage automation, and feedback loops that train the system to distinguish real issues from noise. As a result, our false positive rate has dropped, and we’re able to provide engineers with true security issues and defects to address.
- Safeguarding and governing vulnerability output from frontier AI models is a security priority. When a model finds a critical vulnerability, such as remote code execution, handling that information becomes a security operation in its own right. We have learned a great deal about how to manage this responsibly.
All of this reinforces something I keep coming back to: the same models we use to find vulnerabilities are the ones adversaries will eventually use against us. The only responsible game theory strategy is to continually use frontier AI models to scan and improve our code before an attacker does.
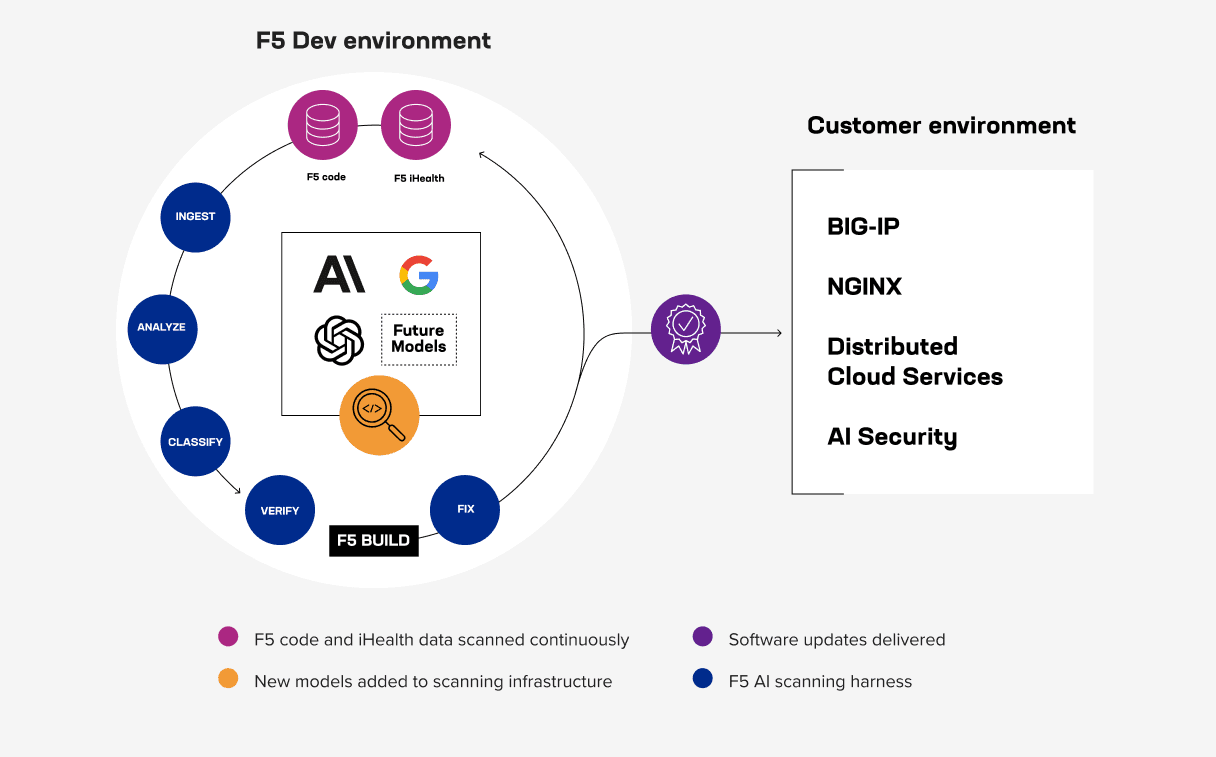
Building tools, harnesses, and processes
We built internal tools that represent a fundamentally different approach to defect analysis and vulnerability management.
Our codebase spans tens of millions of lines of code across C, C++, Python, Tcl, Java, Go, and low-level C written for FPGAs. The issues we’re looking for live in code that’s been running in production for years, across modules that interact in different ways. Building a harness that can reason across that surface, across languages and abstraction layers, was a significant technical challenge.
One of the tools we built ingests new models as they become available from any provider and continuously runs them against our codebase. We are actively engaged with frontier AI labs and have access to some of the most advanced models, including preview and research models. This tool leverages these models along with graph theory, static composition analysis, and more. We also feed in threat intelligence, including public vulnerability and weakness data sets.
This isn’t the only tool in our kit. Our teams have built additional tools that scan for specific classes of defects and leverage work from other organizations. Additionally, many of the frontier labs have highly capable harnesses designed to extract the most from the underlying models.
Regardless of the tool, the scanning infrastructure follows a rigorous, multistep process that looks like the following:
- Ingest. We feed the codebase across major modules and languages so the models can reason over real implementation details, not summaries or abstractions.
- Analyze. We run AI-driven static analysis to detect bugs, risky patterns, and suspicious flows: broken auth logic, insecure crypto, memory safety issues, and more.
- Classify. We extract structured findings, including CWE mappings, severity assessments, file and line references, and exploitability context.
- Verify. A second model confirms, downgrades, or rejects findings before they enter the engineering pipeline. This is where the false-positive problem is challenged. Early on, this step did not exist in any meaningful form, and the noise was overwhelming. Today, it is one of the most important parts of the system.
- Fix. Validated findings are routed into prioritized remediation. Fixes are built, tested, and shipped.
Each cycle builds a knowledge base that makes the next cycle faster and more precise. Over time, the codebase itself becomes more resistant. The models find less because there is less to find. That’s the compounding effect we are investing in.
What we are finding
We’re finding things that exist in virtually every mature codebase: configuration hardening gaps, default settings that should be tightened, memory safety issues (buffer overflows, integer overflows), race conditions, and input validation gaps.
These are exactly the types of issues we want to find and fix. In a world where AI models can reason about how to chain vulnerabilities together, eliminating them systematically makes the entire codebase significantly more resistant to exploitation. These are the building blocks of exploit chains, and removing them makes software harder to attack.
A new muscle: scan, triage, fix, test, release, repeat
One of the most important outcomes of this work is the operational muscle our engineering organization has built over the past several months. Scanning is just one part of an end-to-end capability we built that did not exist before.
We’re moving from a quarterly release cadence to more frequent hardened releases across all software. This is a massive operational shift. Take, for example, the rigor our BIG-IP engineering team applies; they are testing across all active F5OS and TMOS combinations in our customer base. Each combination requires a dedicated test environment. Each release goes through strict branch control, regression testing, and longevity testing. We are documenting upgrade and reboot times and tagging every fix, whether it is a buffer overflow, input hardening, or a CVE, against the release.
We’ve had rigorous scanning and testing practices for years. What’s changed is the AI-driven cycle of scan, triage, fix, test, release, repeat.
What comes next
Expect more releases as AI-driven scanning surfaces more vulnerabilities. This is a sign of stronger security, not weaker software. We’ll disclose what we find, after we publish hardened releases.
As patch frequency increases across the industry, our customers will need to absorb more updates across all vendors, more often. We are committed to making that easier, not harder. We have accelerated work on fleet management, automated updates, and simplified upgrade workflows because these are essential.
Additionally, runtime security has to keep pace. AI-powered detection and response capabilities will be a critical line of defense to identify and stop threats without relying on known signatures or waiting for a patch. We’re building these capabilities because the threat landscape demands it. Expect to hear more from us on this very soon.
Nine months ago, we started exploring whether frontier AI models could fundamentally change how we find and fix vulnerabilities in our own code. They can. The models are better than we expected. Our operational muscle is stronger than we anticipated, and the urgency has only increased.
The organizations that trust us with their most critical infrastructure deserve nothing less.
To learn more, see my previous blog post, “The patch window has closed. Here is how F5 is built for what comes next.”
About the Author

Kunal Anand leads the F5 product organization as Chief Product Officer. Responsible for product vision, strategy, and execution, he ensures development of breakthrough solutions that solve critical challenges and create exceptional experiences for customers. In his previous role as Chief Technology and AI Officer, Kunal charted the company’s technology and AI strategy and vision. Prior to F5, Kunal held the dual role of Chief Technology Officer and Chief Information Security Officer at Imperva. His journey to Imperva began in 2018 with the acquisition of Prevoty, an application security startup he co-founded in 2013. Before joining Prevoty, he was the Director of Technology at BBC Worldwide. Kunal has a deep history of innovation and technical expertise, and has held roles leading security, data, technology, and engineering teams at Gravity, MySpace, and the NASA Jet Propulsion Lab. Kunal has over 15 years of experience in AI and machine learning, ranging from model training, employing AI-driven algorithms to enhance products, and designing and implementing AI architectures. Kunal holds a Bachelor of Science degree in computer science from Babson College.
More blogs by Kunal AnandRelated Blog Posts
Securing the new control points in the AI journey
AI architecture is fundamentally different than traditional IT environments and requires a different security strategy to protect critical AI workloads.
The patch window has closed. Here is how F5 is built for what comes next.
As AI models have changed software security, the industry needs to adapt.

Best practices for optimizing AI infrastructure at scale
Optimizing AI infrastructure isn’t about chasing peak performance benchmarks. It’s about designing for stability, resiliency, security, and operational clarity
Datos Insights: Securing APIs and multicloud in financial services
New threat analysis from Datos Insights highlights actionable recommendations for API and web application security in the financial services sector
Secrets to scaling AI-ready, secure SaaS
Learn how secure SaaS scales with application delivery, security, observability, and XOps.

How AI inference changes application delivery
Learn how AI inference reshapes application delivery by redefining performance, availability, and reliability, and why traditional approaches no longer suffice.