


This blog post is the third in a series about AI data delivery.
Generative AI may seem effortless on the surface. But behind every successful model is a data pipeline as intricate and sensitive as an industrial refinery.
AI leaders consistently note that the biggest obstacle to scaling AI isn’t the models, it’s the data flow that feeds them. McKinsey & Company estimates that enterprise demand for AI-ready data infrastructure is growing more than 30% per year, while the data requirements of model-training environments are expanding even faster. So, when these pipelines falter, even the most advanced GPUs sit idle.
A brief analogy helps frame the challenge.
“Think of an AI data pipeline like a modern manufacturing assembly line. Raw materials (enterprise data) must be collected, inspected, and staged correctly before entering the line.”
They’re then refined through a series of precision steps: cleaning, labeling, converting, and validating, so they meet strict quality standards. Finally, the finished components must be routed efficiently to the right production stations at the right time. If any phase is inconsistent, delayed, or misaligned, the entire operation backs up – just as an assembly line grinds to a halt when one workstation falters.
Just as raw materials must be gathered, refined, and delivered to the production station, enterprise data must move through ingestion, transformation, and delivery before it becomes useful for training/fine-tuning models, or utilized for retrieval-augmented generation (RAG). If any stage becomes contaminated or delayed, the entire AI system is compromised which negatively impacts the business and erodes ROI.
This post examines those three stages and explains how F5 BIG-IP and S3-compatible object storage support the model-foundry workflows that enterprises rely on today.
Phase 1: Ingestion—capturing and consolidating the raw material
Ingestion is the moment when data enters the AI ecosystem. Enterprises rarely have a single source of truth; their “raw materials” exists across departmental systems, cloud services, object stores, SaaS tools, logs, APIs, and even external third-party data. Much of it arrives in differing formats, at different cadences, and with varying levels of integrity.
During this phase, data must be identified, authenticated, normalized, and validated as it makes its way into centralized or distributed object stores. Metadata is attached, schemas are mapped, and early quality checks occur. If ingestion is sloppy, the rest of the pipeline inherits that sloppiness. Model drift, or the degradation of models over time hallucinations, and unstable training jobs often originate from inconsistent or poorly governed ingestion.
This is also where connection fragility becomes a real concern. In many highly distributed environments, long-lived connections to remote systems drop unexpectedly. Without proper safeguards, these failures leave abandoned sessions open in the object storage environment, slowly draining resources and contributing to environment reliability.
F5 BIG-IP provides stability here by managing those connections, preventing runaway resource consumption, and ensuring that data transfers complete predictably even when the network at the source is weak. BIG-IP’s established strengths—built-in authentication (including token validation, identity integration, and mutual TLS), traffic management, API protection, and DDoS defense—also protect the sensitive data being pulled into the organization.
With these guardrails in place, data reliably reaches the S3-compatible storage systems that feed the next stage.
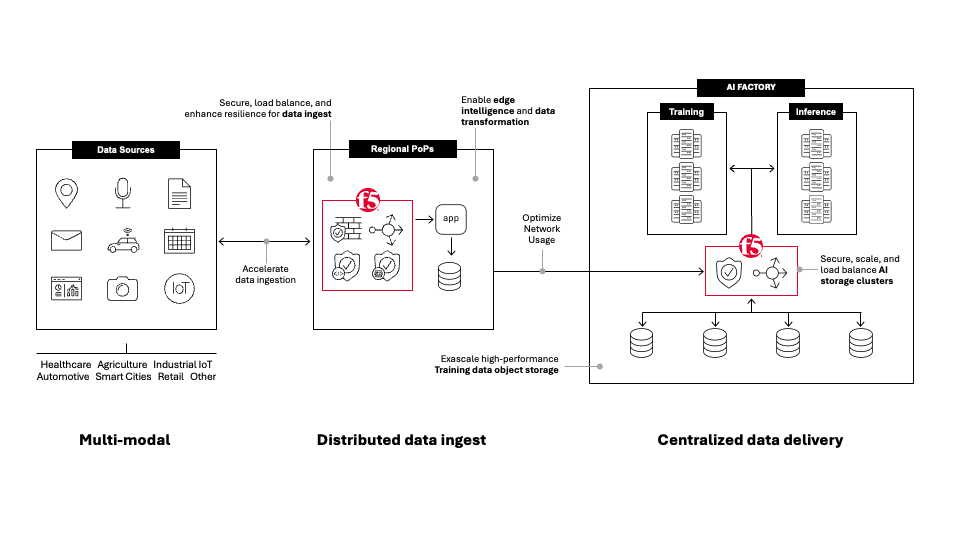
Phase 2: Transformation—refining data into model-ready materials
If ingestion loads the raw material, transformation is the refinery that turns it into high-quality model-ready data assets. The work done here is far more involved than many teams expect, and a surprising number of AI projects falter at this stage. Model-foundry environments depend on consistent, well-governed data; when the data is noisy, inconsistent, poorly formatted, or poorly labeled, training becomes unstable and model quality drops.
Transformation involves cleaning, converting, and preparing data so it can be used for model training, fine-tuning, or retrieval-augmented generation (RAG).
Documents and PDFs become structured text or vector embeddings. Images and logs are parsed into standard formats. Missing values are corrected. Sensitive information is redacted or encrypted. Lineage is recorded so regulators can trace how specific assets were produced or modified. In RAG pipelines, this is also where chunking strategy, embedding generation, and index updates occur.
Traditionally, transformation happened inside a centralized environment, but that pattern is shifting. As data volumes explode, it increasingly makes sense to perform some transformation at the edge or near data sources.
F5 BIG-IP enables distributed enrichment and refinement with flexible form factors that can sit closer to data origin points. When paired with flexible S3-compatible object storage deployed at the edge, organizations can filter and refine data before sending it back to the central pipeline. This reduces traffic costs and minimizes the risk of transferring unnecessary or noncompliant content.
By the time transformation is complete, the organization has clean, trustworthy, and secure assets ready for downstream compute systems.
Phase 3: Delivery—moving optimized data to right compute at the right time
Delivery is the point at which the refined data meets the GPU clusters, fine-tuning jobs, vector databases, or RAG pipelines that depend on it.
The quality of delivery is felt immediately by users and operators. If data arrives too slowly, GPUs starve. If routing is inefficient, jobs queue longer than expected. If access controls are weak, sensitive datasets become exposed.
A well-designed delivery stage ensures that data moves quickly and consistently from storage to compute. High-throughput access paths enable distributed training jobs to read from object storage in parallel. Intelligent caching improves performance.
Automated workflows schedule training runs, scale resources, and route semantic-search queries. Monitoring tools track latency, throughput, and performance anomalies.
Security remains critical here. Access must be controlled at the point of use, not just at ingestion, which ensures that each dataset is only available to the correct models, jobs, or users.
F5 BIG-IP supports this by enforcing policy, validating tokens, and monitoring request patterns. It also optimizes traffic distribution so data flows to compute resources as efficiently as possible.
When paired with scalable S3-compatible storage, these capabilities create an environment that keeps training and fine-tuning jobs continuously fed, reducing idle GPU time and maintaining predictable performance.
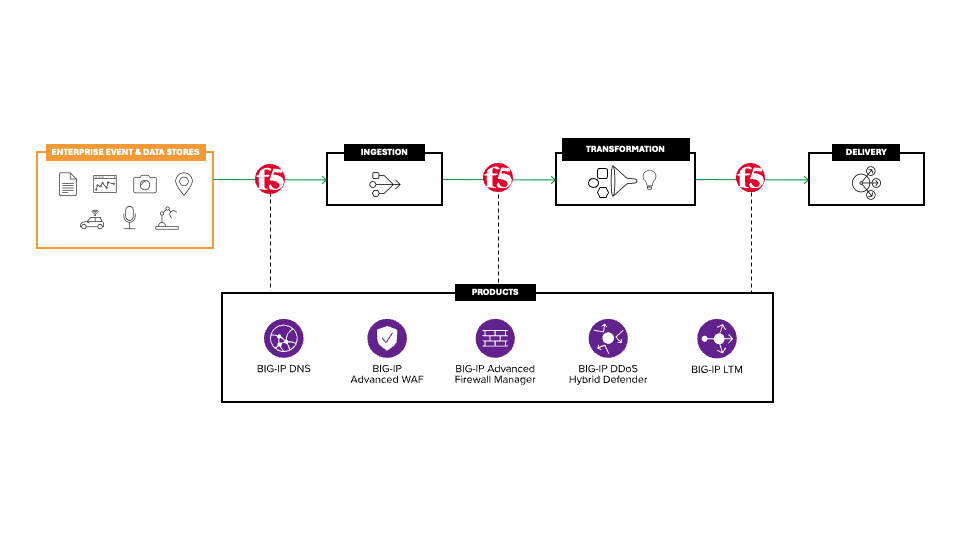
How the three stages come together
Although ingestion, transformation, and delivery are distinct processes, they operate as a continuous cycle.
Ingestion ensures that fresh, governed data enters the system from across the enterprise. Transformation refines that data into high-quality assets suitable for training, RAG indexing, or fine-tuning. Delivery moves those assets to the right compute resources with speed and integrity.
Weakness in any single area slows the entire operation. Also, pipeline breakdowns are pervasive. Overall, more than 80% of enterprise AI projects fail, according to multiple sources, many of which also report that at least 70% to 80% of those failures are attributed to poor or insufficient data quality.
But when the pipeline flows smoothly end to end, supported by secure and resilient network services such as BIG-IP and scalable S3-compatible storage, organizations can train faster, fine-tune more confidently, and operate model-foundry environments at industrial scale.
F5 delivers and secures AI applications anywhere
For more information about our AI data delivery solutions, visit our AI Data Delivery and Infrastructure Solutions webpage.
F5’s focus on AI doesn’t stop with data delivery. Explore how F5 secures and delivers AI apps everywhere.
Be sure to check out the other blog posts in our AI data delivery series:
Fueling the AI data pipeline with F5 and S3-compatible storage
Optimizing AI by breaking bottlenecks in modern workloads
Why AI storage demands a new approach to load balancing
Best practices for optimizing AI infrastructure at scale
Delivering AI applications at scale: The role of ADCs
Secure your AI data pipeline without slowing pipelines down
About the Authors


Mark Menger is a Solutions Architect at F5, specializing in AI and security technology partnerships. He leads the development of F5’s AI Reference Architecture, advancing secure, scalable AI solutions. With experience as a Global Solutions Architect and Solutions Engineer, Mark contributed to F5’s Secure Cloud Architecture and co-developed its Distributed Four-Tiered Architecture. Co-author of Solving IT Complexity, he brings expertise in addressing IT challenges. Previously, he held roles as an application developer and enterprise architect, focusing on modern applications, automation, and accelerating value from AI investments.
More blogs by Mark Menger
Related Blog Posts
Securing the new control points in the AI journey
AI architecture is fundamentally different than traditional IT environments and requires a different security strategy to protect critical AI workloads.
The patch window has closed. Here is how F5 is built for what comes next.
As AI models have changed software security, the industry needs to adapt.

Best practices for optimizing AI infrastructure at scale
Optimizing AI infrastructure isn’t about chasing peak performance benchmarks. It’s about designing for stability, resiliency, security, and operational clarity
Datos Insights: Securing APIs and multicloud in financial services
New threat analysis from Datos Insights highlights actionable recommendations for API and web application security in the financial services sector
Secrets to scaling AI-ready, secure SaaS
Learn how secure SaaS scales with application delivery, security, observability, and XOps.

How AI inference changes application delivery
Learn how AI inference reshapes application delivery by redefining performance, availability, and reliability, and why traditional approaches no longer suffice.